
Представьте, что вы изучаете зарплатное исследование рынка. Вы хотите понять, можно ли на его основе делать выводы и принимать стратегические решения в бизнесе.
Давайте разберёмся:
- Сколько респондентов должно быть в исследовании, чтобы ему можно было доверять
А ещё немножко поговорим о том, что такое:
- Генеральная совокупность
- Репрезентативная выборка
- Уровень надёжности выборки
🙋♂️ Допустим, вы хотите понять, как изменились зарплаты русскоязычных айтишников за 2023 год..
Вот несколько подходов к анализу.
1. Идеальный, но нереалистичный способ
Создаёте реестр всех русскоязычных специалистов из IT-отрасли и опрашиваете каждого лично. А ещё лучше — проводите анализ данных на основании их банковских выписок.
Создаёте реестр всех русскоязычных специалистов из IT-отрасли и опрашиваете каждого лично. А ещё лучше — проводите анализ данных на основании их банковских выписок.
✅ Такой вариант гарантирует 100% точность исследования.
❌ К сожалению, такой вариант вам, скорее всего, не доступен.
2. Повышаем точность до максимума за счёт снижения количества респондентов.
Сужаете запрос до «Как изменились зарплаты 10 продуктовых аналитиков в компании N за 2023 год». Опрашиваете всех лично и получаете точные данные.
Сужаете запрос до «Как изменились зарплаты 10 продуктовых аналитиков в компании N за 2023 год». Опрашиваете всех лично и получаете точные данные.
✅ 100% точность за счёт малого количества целевых респондентов.
❌ Данных недостаточно, чтобы делать выводы об изменение з/п продуктовых аналитиков в других компаниях.
3. Реалистичный способ
- Принимаете как данность, что до всех нужных респондентов дотянуться не получится.
- Рассчитываете, какое количество респондентов будет корректно отражать реальность (генеральную совокупность; про неё — ниже).
- Оцениваете допустимую погрешность (про это тоже см. ниже). Рассчитываете, сколько респондентов нужно опросить, чтобы можно было доверять полученным данным.
- Проводите опрос достаточного числа респондентов.
- Используете полученные данные, учитывая допустимую погрешность.
Ликбез про генеральную совокупность и уровень надёжности выборки
Генеральная совокупность — все подходящие нам респонденты
- Например, если мы хотим узнать зарплаты всех разработчиков, то генеральная совокупность — это вообще все такие специалисты в мире.
- Например, мы не можем проанализировать зарплаты вообще всех разработчиков в мире (генеральной совокупности). Поэтому мы исследуем только часть этих разработчиков. Эту часть мы называем «выборкой».
- Например, те разработчики, которых мы опросили, должны быть максимально похожи на всех разработчиков в мире.
- Вопрос в том, сколько должно быть человек в такой выборке. Этот вопрос решается формулой. Есть готовые калькуляторы для расчёта. Но чтобы воспользоваться этим калькулятором, нужно знать ещё несколько понятий ⬇️
- Хорошим уровнем надёжности считается 95%.
- То есть если в вашей выборке разработчики получают в среднем 150 000 рублей, то в 95% случаев остальные разработчики (в генеральной совокупности) тоже получают 150 000 рублей. Но при этом у оставшихся 5% всех разработчиков средняя зарплата будет отличаться. Она будет больше или меньше 150 000 рублей.
- Если уровень надёжности выше 95%, мы счастливы. Если ниже, то это значит, что наши данные менее репрезентативны. Таким данным тоже можно доверять, но у них будет бо́льшая погрешность.
- Какая погрешность считается нормальной? ⬇️
- Это те самые 5% разработчиков, из генеральной совокупности, которые получают больше или меньше150 000 рублей. То есть ведут себя не так, как разработчики в вашей выборке.
- Для маркетинговых и бизнес-исследований есть стандарт, что погрешность не должна превышать 4-5%.
Какой должна быть доступная выборка, чтобы считаться репрезентативной?
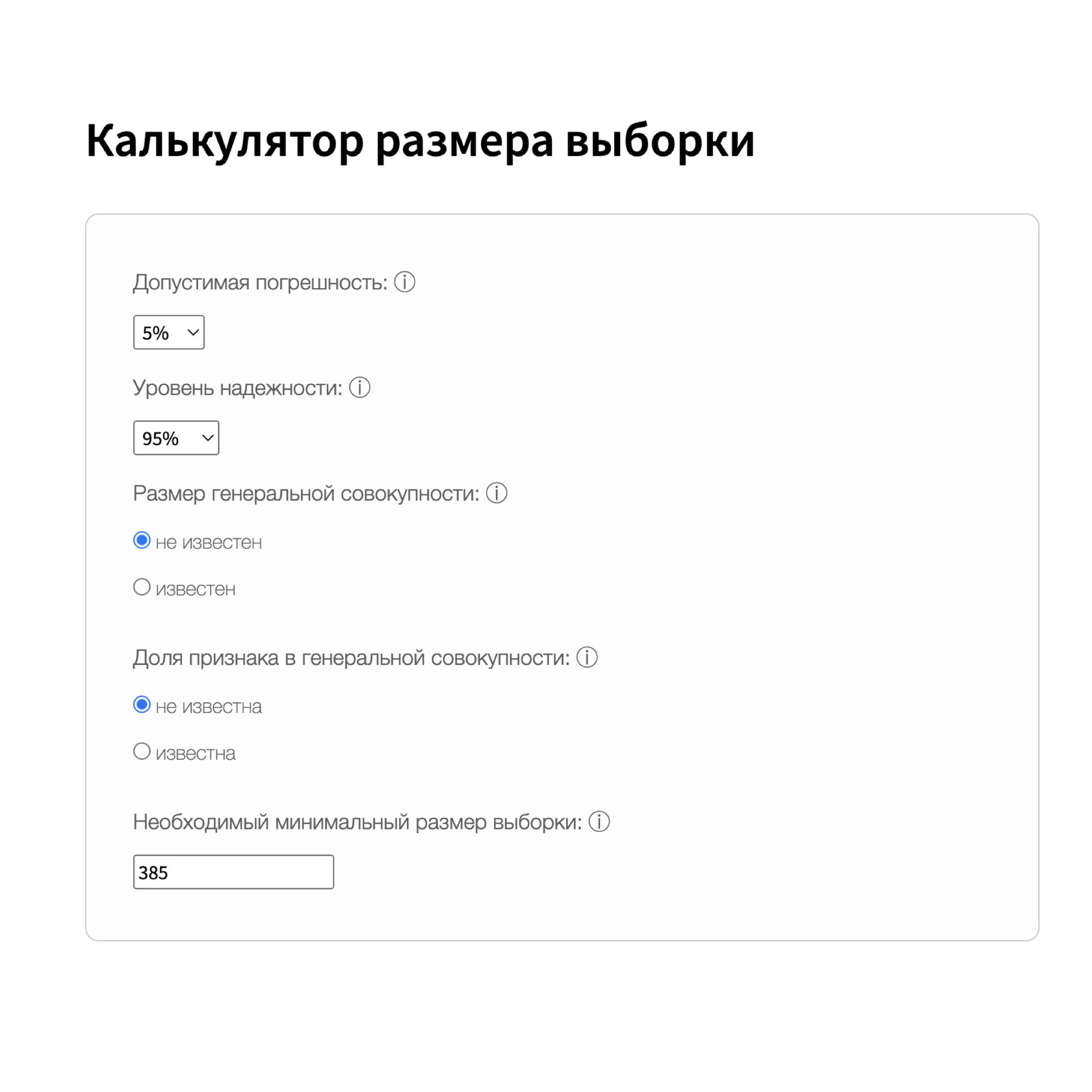
Воспользуемся калькулятором.
Для нашего исследования зарплат всех разработчиков, мы хотим:
- 5% допустимой погрешности. Чтобы мы могли смело опираться на полученные данные.
- 95% уровень надёжности исследования. По той же причине.
- Размер генеральной совокупности нам не известен. Мы не знаем точно, сколько всего разработчиков существует в мире.
- Долю признака в генеральной совокупности мы тоже не знаем. То есть мы не знаем, сколько среди всех разработчиков мира джунов, мидлов и сеньоров, чтобы учесть это при составлении нашей выборки и опросить такие же доли людей этих грейдов.
Результат по формуле:
Нам требуется опросить 385 человек.
Как можно ещё больше повысить репрезентативность выборки
Стоит стремиться к тому, чтобы сделать выборку максимально однородной.
Пример повышения однородности выборки:
- Все айтишники
- Только разработчики
- Только фронтенд-разработчики
- Только senior фронтент-разработчики
- Только senior фронтенд-разработчики, говорящие на русском языке
📌 Чем более однородная выборка, тем больше мы можем доверять результату исследования